This article is the part of series Mastering Index, in this particular article we will be exploring Nonclustered Index. Take a look at the content of this series -
One of the most interesting and talked about topic in database field is Index. I am writing this Series of article to cover all the different types of index available in SQL Server. I will be writing this series in two categories Index and Special Index. Please find the List of topics below, which I will covering –
Mastering Index
1. Clustered Index
2. Nonclustered Index
3. Unique Index
4. Index with included columns
5. Index on computed columns
6. Filtered Index
Special Index
1. XML Index
2. Full Text Index
3. Spatial Index
4. Columnstore Index
Nonclustered Index
As you remember from our previous article of this series, Indexes are used to speed up the data retrieval from table or view. Clustered index physically organize the data and we can create only one on a table. Good news is that we can create multiple Nonclustered indexes on a table and the limit is 999 per table. When we create a Nonclustered index, SQL Server creates a B-Tree structure for that, which looks something like below diagram. On top we have the root node, in bottom we have leaf nodes and between them are intermediate or non leaf nodes. In a Nonclustered index, leaf nodes contain pointer to row id (RID) if our table is a heap or index key for clustered index and included columns(We will be discussing include columns later in the article). So in some situations Nonclustered index use the clustered index to read the data from table.
The diagram show us the internal structure of the Nonclustered index. Here you can see that only difference between clustered and Nonclustered index leaf node is that Nonclustered index leaf node contains RID or Index key and included columns.

Let’s see how Nonclustered index internally uses the clustered index to fetch the data. When our Nonclustered index leaf node doesn’t have all the information we need then SQL Server reads the RID/ Index key from it and search it in clustered index. Once it finds it there, it returns us the information.
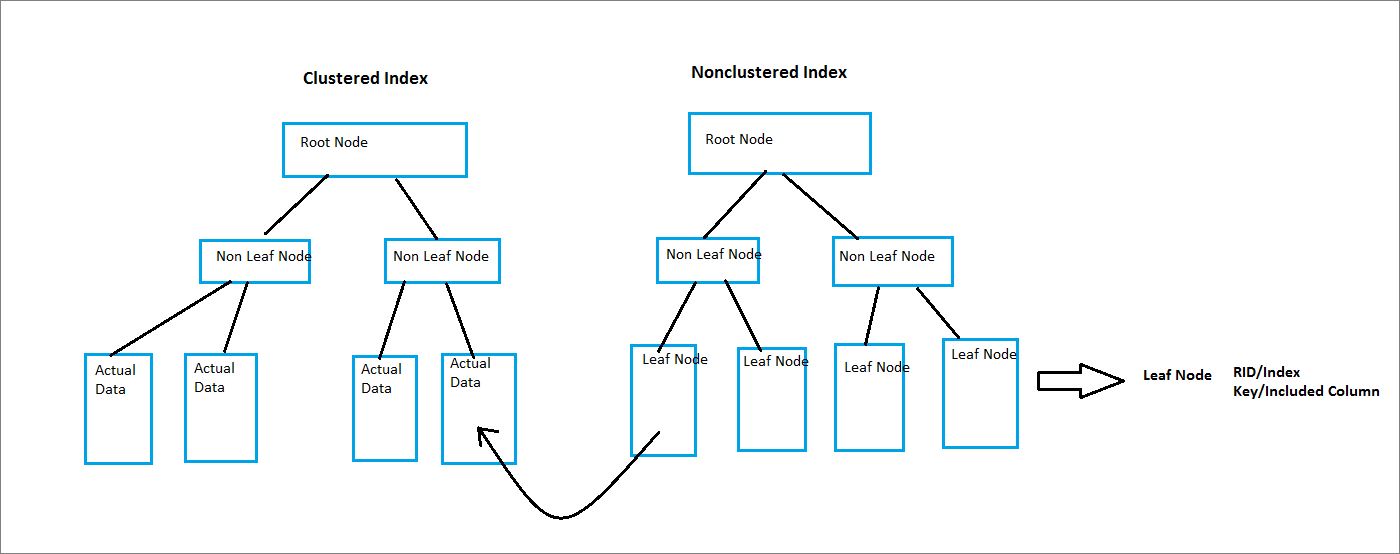
Below diagram shows us that leaf nodes of Nonclustered and clustered index respectively. Here we have a Nonclustered index on the First Name column of the table and clustered index on the ID column of the same table. Suppose we have a query which finds the Last Name of the person whose first name is ‘Dev’. In this case SQL Server starts with searching the first name in Nonclustered index, once it finds it. It reads the ID of the person and goes to clustered index and look for the same ID. Once it finds the ID, it accesses the full record and reads the last name from it.

Creating Clustered Index
Before we create any index, let’s create a table for testing. Here is the script for that. This script creates an EmployeeTest table and uploads data from Employee table of AdventureWorks database. I am using SQL Server 2014, you may need to modify the script as per your version of SQL Server. You may notice that I am using a while loop to create the enough data load, so we can see performance improvement by using Nonclustered index.
USE [AdventureWorks2014]
GO
/****** Object: Table [HumanResources].[Employee] Script Date: 10/7/2016 12:38:57 PM ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
Begin
CREATE TABLE [HumanResources].[Employee_Test](
[BusinessEntityID] [int] Identity NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] int,
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [dbo].[Flag] NOT NULL DEFAULT ((1)),
[VacationHours] [smallint] NOT NULL DEFAULT ((0)),
[SickLeaveHours] [smallint] NOT NULL DEFAULT ((0)),
[CurrentFlag] [dbo].[Flag] NOT NULL DEFAULT ((1)),
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL DEFAULT (newid()),
[ModifiedDate] [datetime] NOT NULL DEFAULT (getdate()),
)
Declare @Count int
Declare @TotalRec int
Set @Count=0
Set @TotalRec=300
WHILE (@TotalRec>@Count)
BEGIN -- While Begin
Insert into [HumanResources].[Employee_Test]
(
[NationalIDNumber]
,[LoginID]
,[OrganizationNode]
,[OrganizationLevel]
,[JobTitle]
,[BirthDate]
,[MaritalStatus]
,[Gender]
,[HireDate]
,[SalariedFlag]
,[VacationHours]
,[SickLeaveHours]
,[CurrentFlag]
,[rowguid]
,[ModifiedDate]
)
SELECT
[NationalIDNumber]
,[LoginID]
,[OrganizationNode]
,[OrganizationLevel]
,[JobTitle]
,[BirthDate]
,[MaritalStatus]
,[Gender]
,[HireDate]
,[SalariedFlag]
,[VacationHours]
,[SickLeaveHours]
,[CurrentFlag]
,[rowguid]
,[ModifiedDate]
FROM [AdventureWorks2014].[HumanResources].[Employee]
set @Count=@Count+1
END
End
Create Clustered Index
Use below script to create a clustered index or you can use management studio using GUI. You can find steps in previous article of this series.
USE [AdventureWorks2014]
GO
/****** Object: Index [ClusteredIndex-20161007-142145] Script Date: 10/7/2016 2:33:09 PM ******/
CREATE UNIQUE CLUSTERED INDEX [ClusteredIndexEmpTest] ON [HumanResources].[Employee_Test]
(
[BusinessEntityID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
Once you have created the Index, let’s run the below script to see how index is useful. Please select include actual execution plan. You can select that option from right click and select from list or directly from tool bar.

DBCC FREEPROCCACHE
Go
select nationalIDNumber,LoginID,JobTitle from [HumanResources].[Employee_Test] T where T.nationalIDNumber=253022876
As you can see in the actual execution plan, all execution cost is used in scanning clustered index because clustered index is created on nationalIDNumber and SQL Server doesn’t need any other information or no need to access any other table to get the selected data, So all resources has been used to scan only clustered index.

Create Nonclustered Index
Let’s create our first Nonclustered index on NationalIDNumber column. You can use the below script or GUI to create the script.
USE [AdventureWorks2014]
GO
/****** Object: Index [NonClusteredIndexNationalIDNumber] Script Date: 10/7/2016 2:33:15 PM ******/
CREATE NONCLUSTERED INDEX [NonClusteredIndexNationalIDNumber] ON [HumanResources].[Employee_Test]
(
[NationalIDNumber] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
Step 1- Expand the table property, select and right click the Index folder. Select New Index > Nonclustered Index.

Step 2- Give an informative name to your index and click Add button to select columns. Here we are creating index on nationalIDNumber, so select it from the list and click OK. You can see your newly created index in Index column. If it is not there, please refresh the index folder.

Once index is ready, let’s run the same script and analyze the execution plan.
DBCC FREEPROCCACHE
Go
select nationalIDNumber,LoginID,JobTitle from [HumanResources].[Employee_Test] T where T.nationalIDNumber=253022876

As you can see in execution plan, now our cost is distributed among index scan and key look up. When we execute the above script , SQL Server scan the Nonclustered index on the NationalIDNumber column and once it’s find ‘253022876’ it gets the Clustered index key value from leaf node of Nonclustered index. In next step it performs the key lookup operation on clustered index and once it finds the value ‘253022876’, it reads the remaining values from there. As you may remember clustered index leaf node contains the data row. Just think about it, what if SQL Server can store the LoginID and JobTitle in Nonclustered index leaf node. Yes we can do that by using the include column option and we can save all the effort used in Key lookup in clustered index.
Index with include column
As I explained earlier, leaf node of the Nonclustered index keeps the Row ID of the heap or Index key of the table to access the full record. If your most of the queries fetch certain column values from the table, you can think about using Include column option. Suppose whenever you write a query filtered on NationalIDNumber, you fetch LoginID and JobTitle with that. In this case you can include these columns in the Nonclustered index and save the time and resource to scan the clustered index to fetch the additional information. Here is the syntax to create a Nonclustered index with include column option. You can use management studio GUI to create the same.
USE [AdventureWorks2014]
GO
/****** Object: Index [NonClusteredIndexIncludeColumn] Script Date: 10/7/2016 2:33:22 PM ******/
CREATE NONCLUSTERED INDEX [NonClusteredIndexIncludeColumn] ON [HumanResources].[Employee_Test]
(
[NationalIDNumber] ASC
)
INCLUDE ( [LoginID],
[JobTitle]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
Step 1- Select Index folder and right click. Select Nonclustered index from the list.

Step 2- Give a proper name to your index and select the column, you want to index. In this case NationalIDNumber.

Step 3- Click on tab Included Columns, next to Index Key Columns and then click Add. Now select columns you want to include in the leaf nodes of the Nonclustered index and click ok.

Step 4- Review the information once again and click OK to create a Nonclustered index with include column.

Step 5- Now our index is ready, if you want to cross check. Select the index then right click and select Script index as >Create to >New Query Editor Window. You will get the create index script and you can see two columns have been included.

Filtered Index
We can create a Nonclustered index with filter criteria, which can improve a query performance in certain situations.
I have a separate article for filtered index, I would recommend you to read it.
Deleting/ Dropping Index
You can use the Drop command or delete from GUI.
Select Index >Right Click>Select Delete>Click Ok on popup window
USE [AdventureWorks2014]
GO
/****** Object: Index [NonClusteredIndexIncludeColumn] Script Date: 10/7/2016 2:36:29 PM ******/
DROP INDEX [NonClusteredIndexIncludeColumn] ON [HumanResources].[Employee_Test]
GO
Important DMVs
sys.indexes
sys.index_columns
sys.dm_db_index_physical_stats function
sys.dm_db_database_page_allocations function
sys.dm_db_missing_index_details
sys.dm_db_missing_index_groups
Interview Questions
Q. Explain the difference between clustered and Nonclustered index?
Q. How many clustered index we can create on a table?
Q. What is Unique index?
Q. Can we force SQL Server to use a particular index?
Q. How many columns we can include in a Nonclustered index?
Q. What is fill factor in Index?
Recommended Book for this Topic
Related Articles -
Mastering Index – Clustered Index
Mastering Index – Introduction